Understanding Large Language Models, in Plain English - Part 1
A Large Language Model (LLM) is a computer program that is trained on an enormous amount of text so that it can understand and generate human language.

If you are like me, this article is dedicated to you.
What is a Large Language Model?
A Large Language Model (LLM) is a computer program trained on an enormous amount of human language.
The idea behind this training is simple.
When a model is trained on enough human language, it picks up the statistical patterns in it.
"Statistical patterns" simply mean:
- Which words often go together
- Which sentence structures are common
- Which words are likely to follow other words
And once the model learns these patterns, it can respond to what you write in a way that feels like a real person.
This ability allows LLM to do useful tasks such as:
- Answering questions
- Writing code
- Drafting emails, articles, and summaries
- You'll see many more things across this series
That is the core idea behind an LLM: Learn patterns in human language and use those patterns to generate useful responses.
Before we go deeper into LLMs, let's first talk about how humans learn language.
Once you understand that, the way LLMs work will make much more sense.
Ready?
How a small child learns language
Imagine a two-year-old child.
Nobody gives her a grammar book or teaches her language rules step by step.
Instead:
- She hears people talking all the time
- Mom talks
- Dad talks
- Siblings shout and play
- The TV runs in the background
For the first few years of her life, she is surrounded by language every day.
Then she starts making sounds, copying words, and watches how people react.
And slowly, she begins noticing patterns.
For example, “milk” appears when a bottle appears.
The word “doggie” appears when the family dog appears.
Phrases like “Can I have…?” are often used when someone wants something.
After a while, she starts making her own sentences.
Sometimes she gets them wrong.
For example, she might say “I goed to the park”.
Why?
Because she noticed a pattern that many past-tense words end with “-ed”.
So she applied that pattern to every word.
After a while, she also realizes that not all words follow that rule.
So, she starts using “went” instead of “goed”.
Nobody manually taught her grammar rules.
She learned them naturally by hearing language again and again and noticing patterns.
That is how children learn their first language.
Not from textbooks.
Mostly from listening, observing, and spotting patterns.
How older kids and adults pick up new language patterns
We do the same thing all our lives.
Let's just say a new student joins your class, and he becomes your best friend instantly.
And within a few weeks, you start using some of his phrases.
Similarly, your cousin visits from another city, and by the time they leave, you've picked up some of their words.
Come on, let's have a quick exercise.
Fill in the blanks:
- Once upon a ___
- How are ___?
You didn't have to think.
The right word came to your mind on its own.
That is your brain spotting patterns in real time.
Yes, adults can also learn formally by using vocabulary lists, grammar lessons, and language apps.
But most of what you know about a language happens naturally through repeated exposure.
Your brain does not memorize every sentence you hear.
Instead, it learns:
- Which words often appear together
- Which sentence structures are common
- Which phrases sound natural
- Which word combinations sound strange
And in computer science and AI, these repeated language patterns are called statistical patterns.
So, what are statistical patterns?
Here are some simple examples:
- Words that often appear together
(“salt and pepper”, “dal and chawal”) - Common sentence structures
(questions often start with “what,” “how,” or “why”) - Relationships between ideas
(“Delhi → India”, “Tokyo → Japan”) - Grammar patterns
(In English, we say “tall boy,” not “boy tall”) - Writing styles
(A school essay sounds very different from a WhatsApp message)
And they are called “statistical” because they are learned by observing:
- How often words appear together
- What order do words usually follow
- Which sentence patterns appear repeatedly
And this learning happens across huge amounts of language data.
Not from grammar rules manually written by humans.
Humans naturally learn these patterns from the language around them.
LLMs also learn these patterns.
But there are some important differences.
How LLMs are different from humans, even if they sometimes look similar
This is the part many people misunderstand. I was one of them.
Before understanding how we are different from AI, let's quickly see how we are similar.
First, just like us, LLMs also learn from huge amounts of language.
During training, they learn:
- Which words often go together
- Which sentence structures are common
- Relationships between ideas
- Grammar patterns
- Writing styles
And just like humans, nobody manually writes grammar rules into the model.
The model learns those patterns by seeing language again and again.
But what is the difference then?
Simple.
Humans learn from real life. Early and text-focused LLMs mostly learned from text.
When you learned the word “milk,” you:
- drank it
- spilled it
- saw its colour
- touched the bottle
In your case, the word "milk" was connected to a real experience.
An LLM does not experience the world like that.
It does not experience milk in the physical world. It does not drink milk or interact with it.
It only learns how the word is used in language.
Next...
Humans learn through interaction. LLMs mostly do not.
A child learns by interacting with people.
A kid asks for milk.
She either gets it or she doesn't. That changes how she asks next time.
An LLM does not have a real conversation with the world.
Instead, an LLM mostly learns by reading huge collections of existing text.
Next...
Humans need much less data
Children learn language from relatively limited exposure over a few years.
But an LLM needs trillions of words to get good. That is tens of thousands of times more than what we humans need.
I am simply trying to convey that humans are much more efficient learners.
LLMs compensate by training on vastly more data, though.
Finally...
Humans use language for goals. LLMs do not.
Kids use language to get food, get attention, and play.
And we adults use it to communicate work, make plans, share ideas, and stay in touch with our friends.
Simply put, language helps humans achieve goals in the real world.
But an LLM does not have personal goals or desires.
It is just guessing the most likely next word.
Ufff...so many differences, but I hope you get the point.
So when people say “LLMs learn exactly like humans”, please understand that is not fully true.
The pattern-learning part is somewhat similar.
But humans also learn through:
- real-world experience
- interaction
- emotions
- goals
- physical senses
LLMs do not.
As simple as that.
Also, please keep this idea in mind throughout the article.
When I say “the LLM learned patterns during training”, I mean it in a narrow mathematical sense.
Not in the same way humans learn and experience language.
Anyway, now this misconception is out of the way, here comes the next important question...
Where does LLM training data come from?
When I said an LLM is trained on "an enormous amount of human language," here's what I meant:
- Billions of pages of books
- Internet articles
- Millions of websites
- Millions of conversations
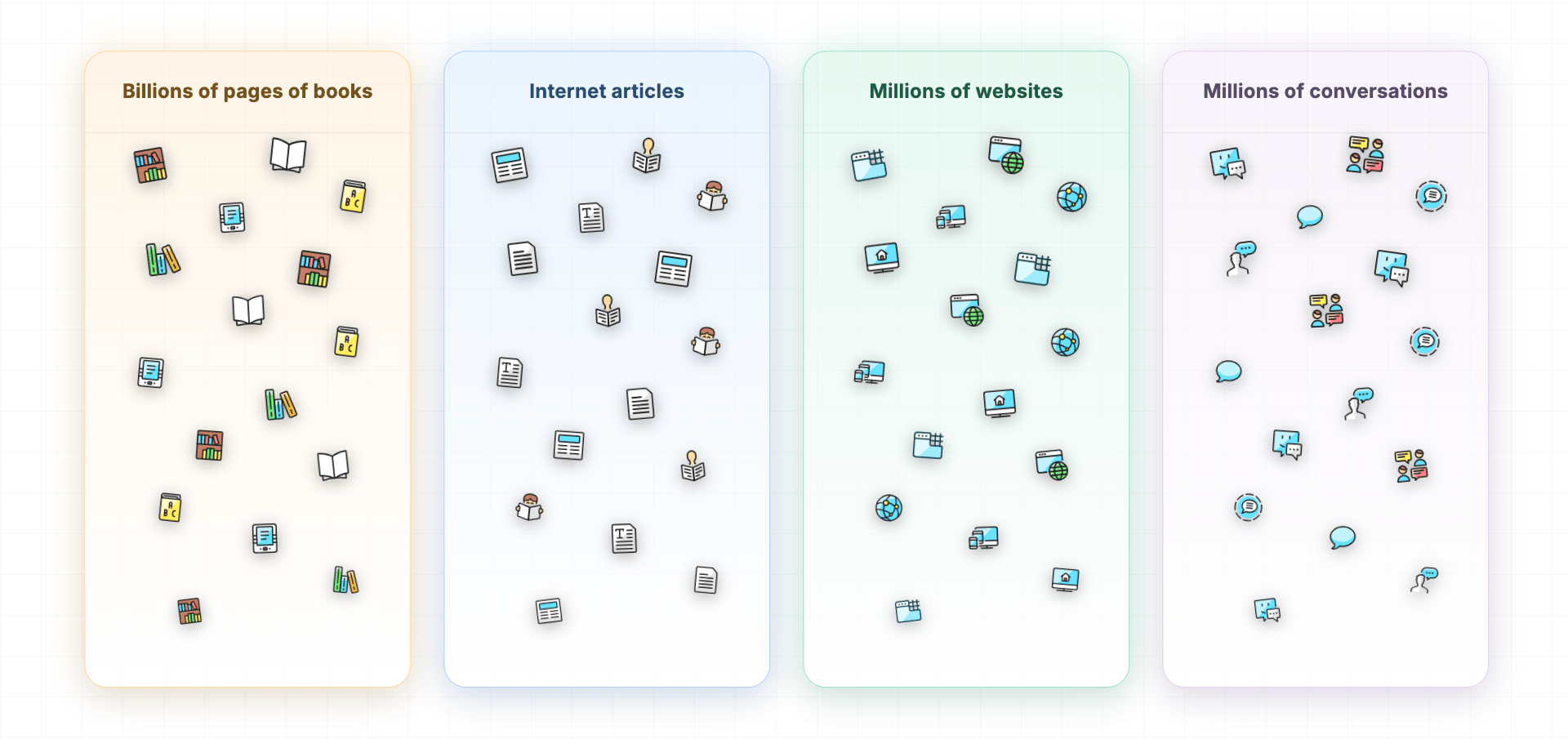
And "human language" doesn't just mean English or Chinese.
Modern LLMs are trained on text in many major world languages, such as English, Hindi, Telugu, Tamil, Bengali, Spanish, Mandarin, Arabic, French, Japanese, German, and many more.
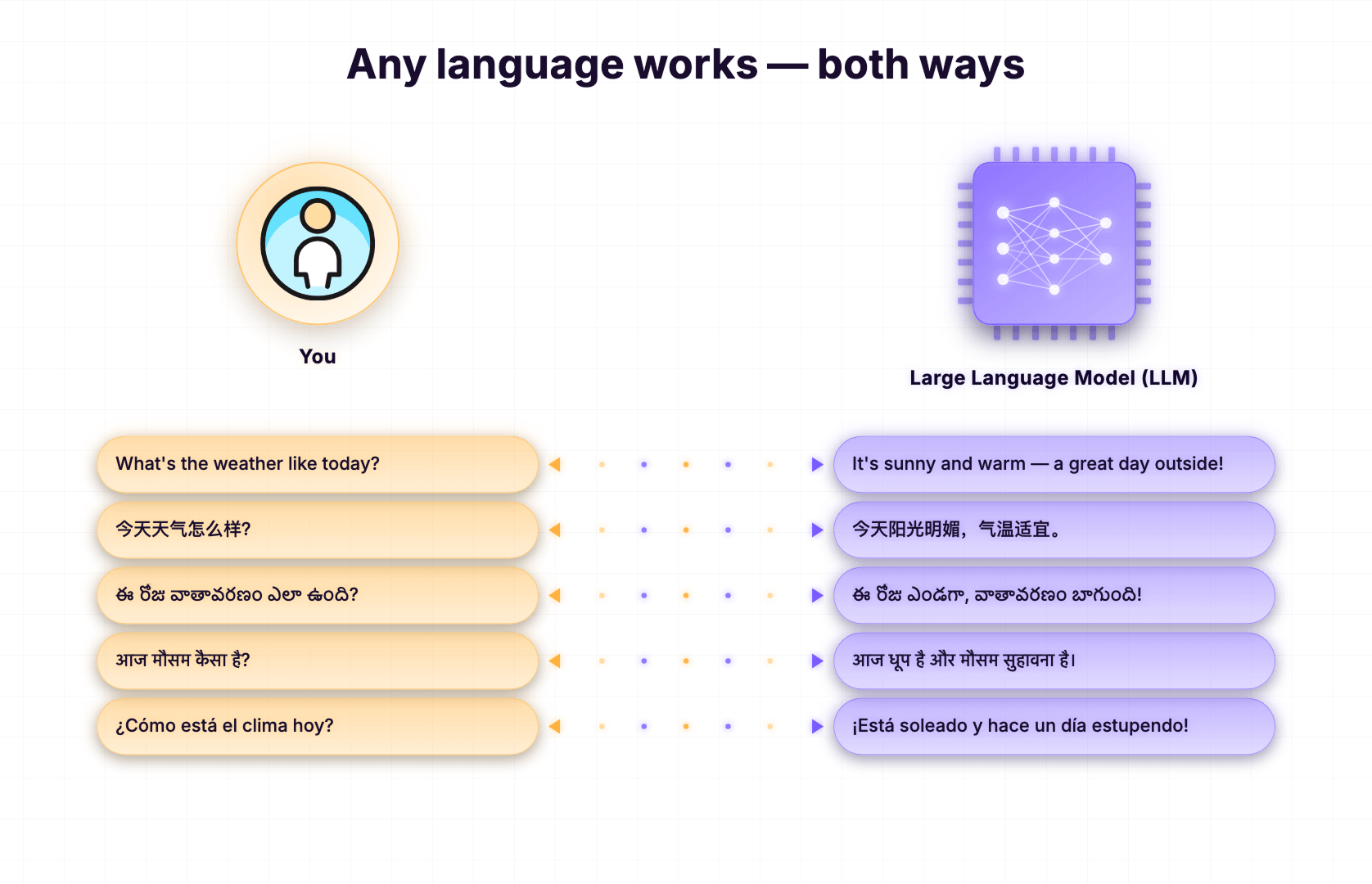
So an LLM might handle a language very fluently but struggle with a low-resource language like Yoruba or Sindhi.
This is why you can chat with ChatGPT in your own native language, and it replies back in the same language.
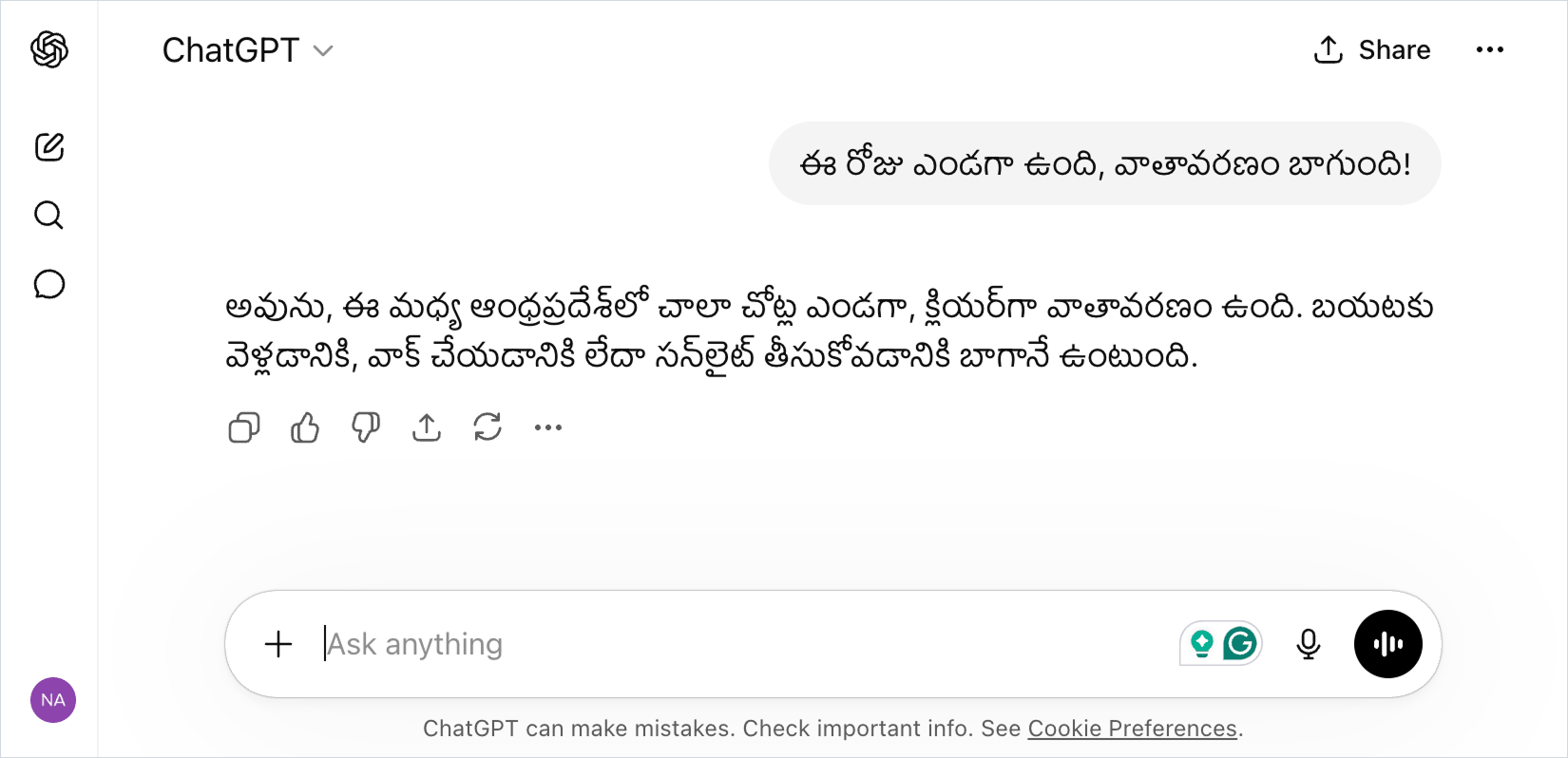
In the above image, I told ChatGPT that "Today's weather is good" in my mother tongue, Telugu, and it responded back in Telugu, agreeing with my statement.
And honestly, this is a huge deal.
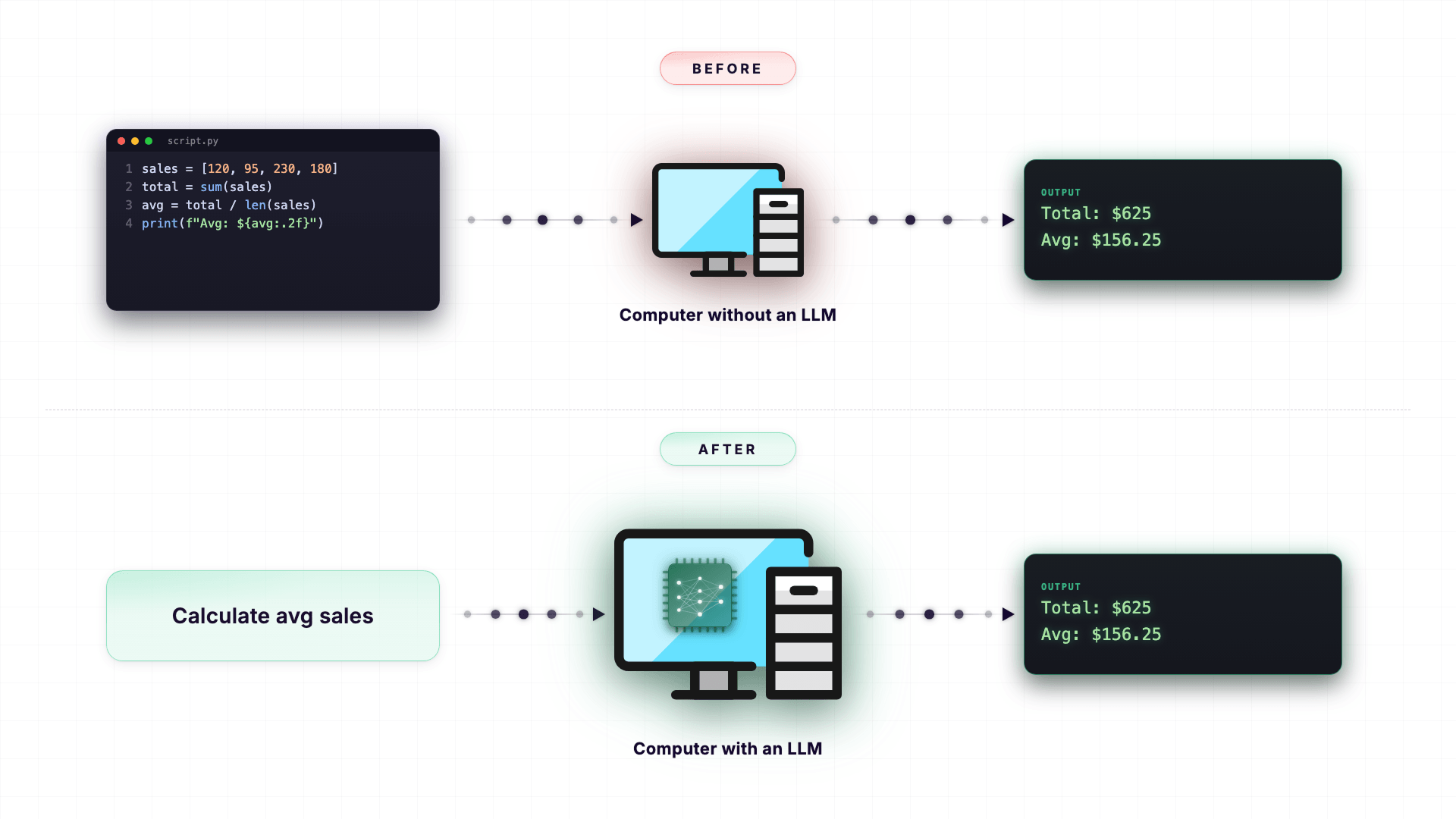
Because, for decades, the only way to really make a computer do something useful was to write code in a programming language like Python, JavaScript, or Java.
If you wanted a computer to do anything beyond simple commands, you had to 'talk' to it in a programming language. Not in human language.

But the introduction of LLMs changed this completely.
Now, you can just type in plain English (or any other human language), and the LLM often responds as if it understood what you meant.
No code.
No special syntax.
Just normal, everyday conversation.
Come on, let's see this in action.
LLM is the heart of ChatGPT. So, open up ChatGPT and ask:
What is the difference between finish and complete?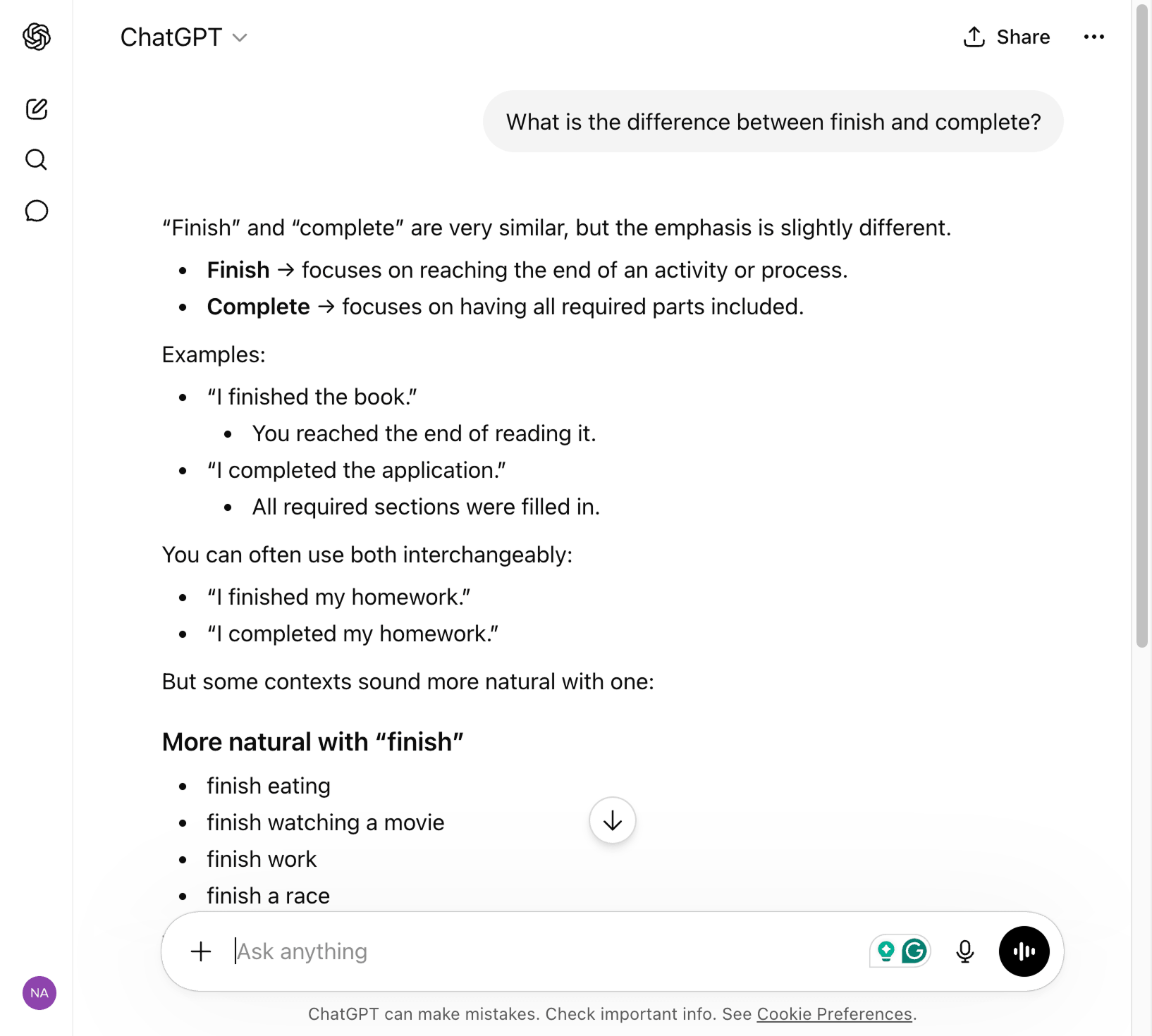
As you can see, you'll get a clear, plain-English explanation for your query.
That is an LLM in action.
It recognized the pattern of what you asked and generated a response based on the patterns it learned during training.
Also, just to be on the same page, ChatGPT is not an LLM.
It is an app that is powered by an LLM.
It is a UI for interacting with an LLM called GPT (Generative Pre-trained Transformer).
The same goes for other LLM apps.
For example, Claude.ai is built on Claude models. gemini.google.com is built on Gemini models, and so on.
OpenAI first developed GPT, and to make it accessible for everyone, they built ChatGPT as a chat UI on top of it.
These days, when I am chatting with ChatGPT, I genuinely feel like I am talking with a Human.
When I speak with Claude Opus (another LLM), I feel like I am getting scolded by a short-tempered mentor.
"Hahaha! Things are definitely getting out of hand."
Yeah, I can see that too.
Anyway, let's dive a bit deep now.
Let's understand the meaning behind the words "Large", "Language", and "Model" because these words say what an LLM truly means.
Let's start with the word "Model".
What does the word "Model" mean?
In the world of AI, a "model" is a computer program that has learned patterns from data.
The data can be text, image, voice, etc.
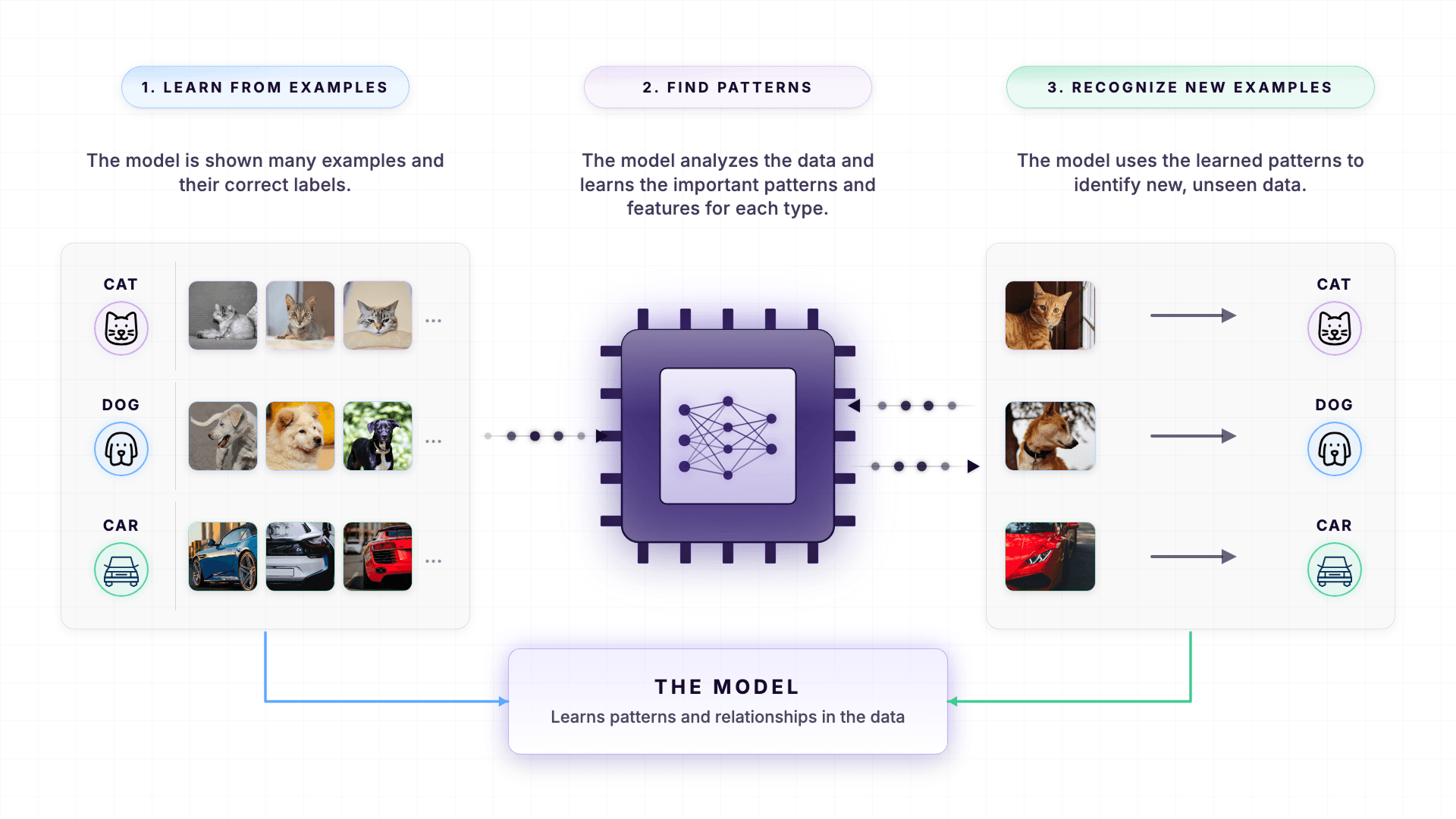
You know that an AI can recognize pictures of animals and humans, right?
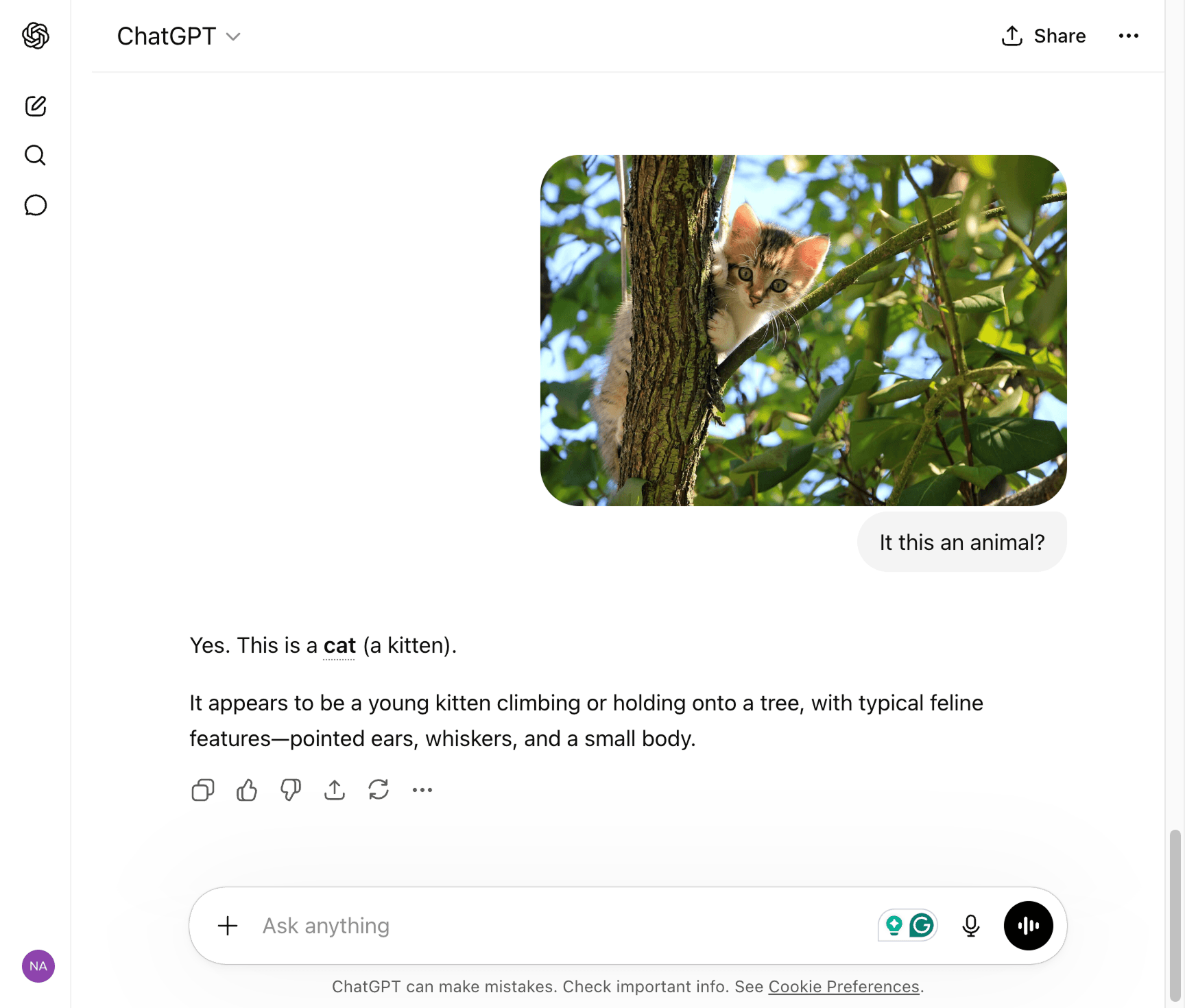
For example, I uploaded a picture of a cat (a kitten), and the AI model behind ChatGPT recognized it.
The surprising part is that the model was also able to recognize a cat in the dark, even though the cat's body or facial features are not clear:
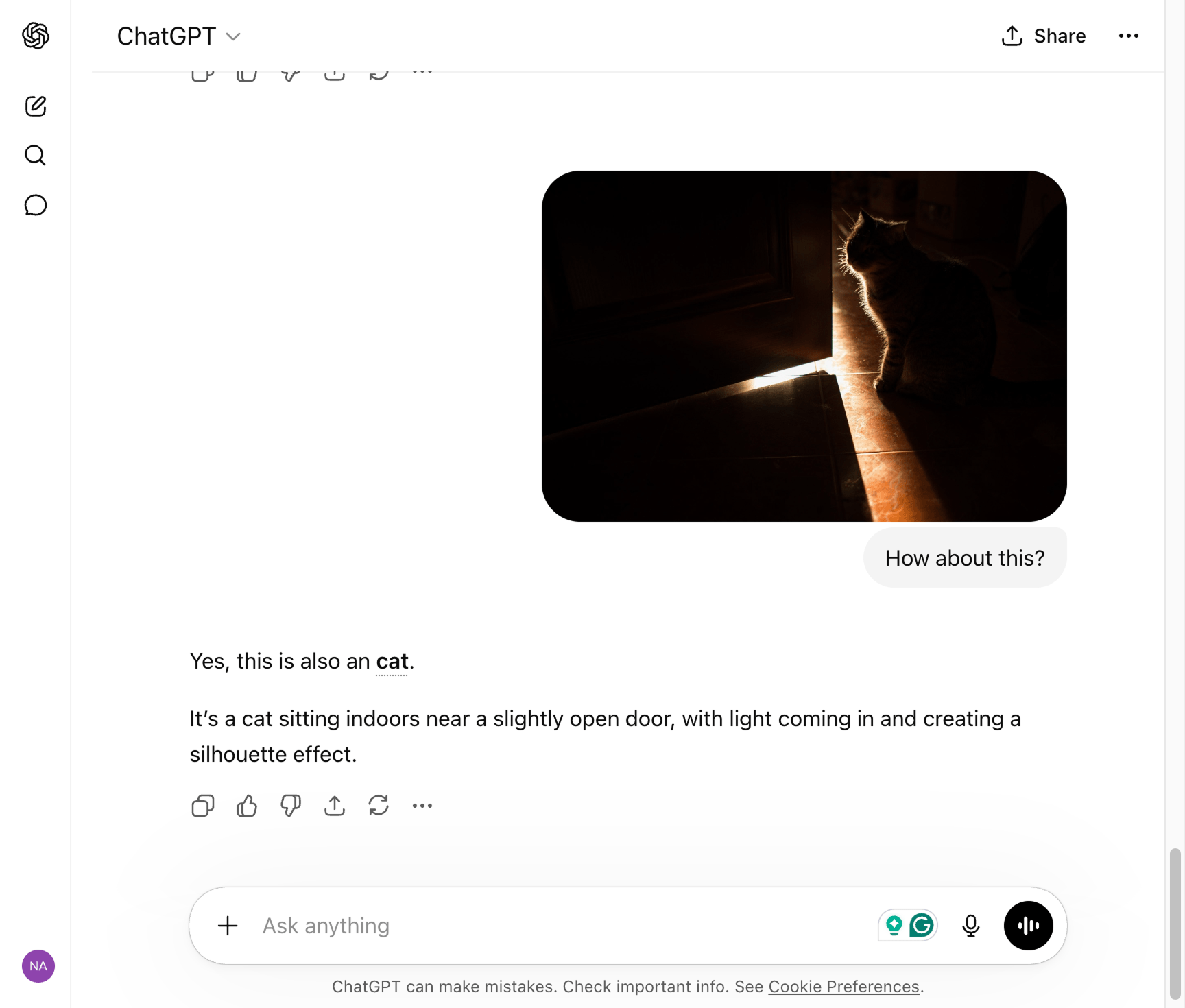
This is possible because the AI model was fed with hundreds of thousands of cat photos to help the model learn the patterns of how a cat looks under any kind of lighting conditions and angles.
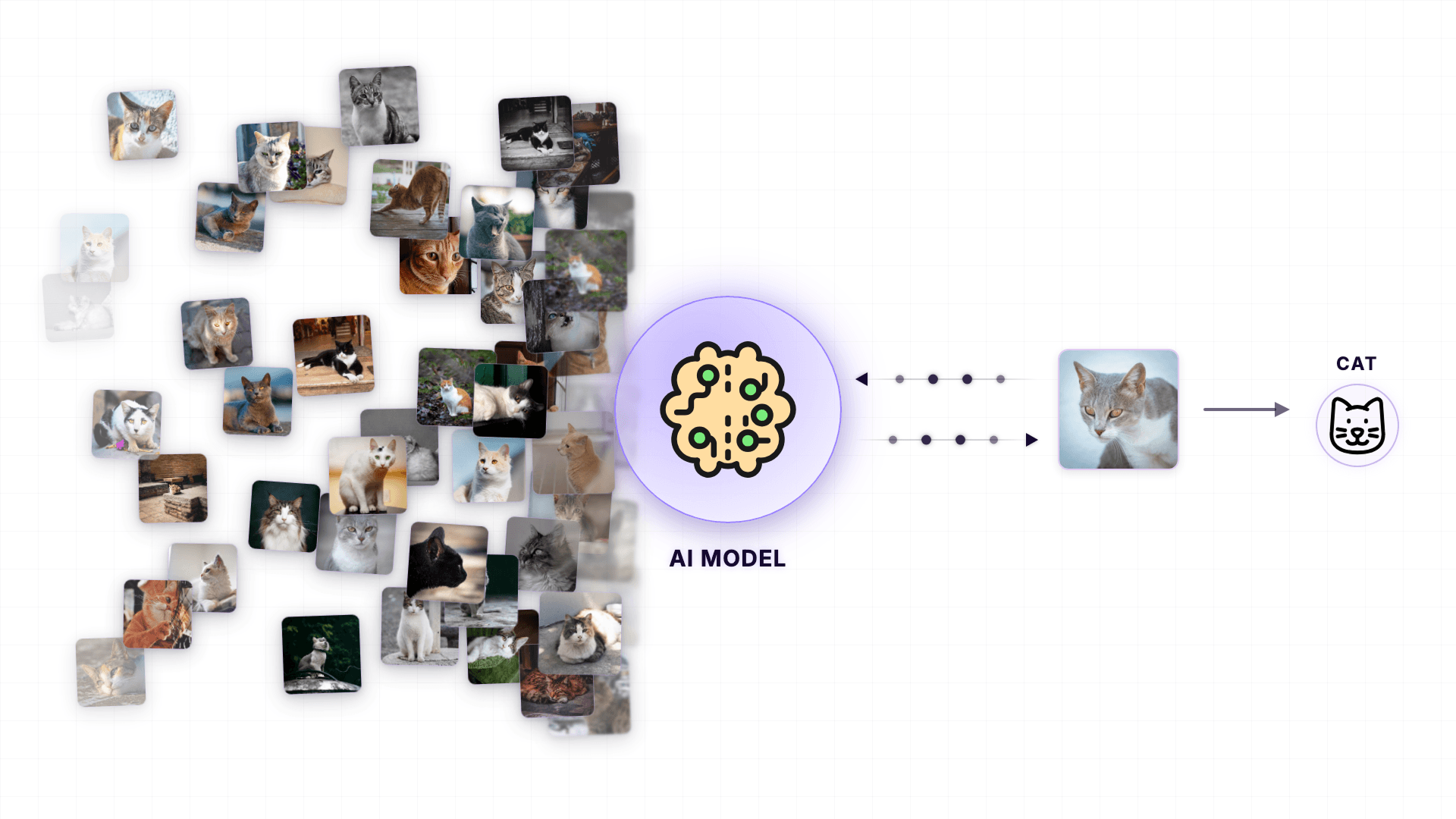
The same happens with text.
LLMs are trained on billions of sentences from books, articles, forums, and websites.
But the LLM is not just "reading" these sentences.
It is being trained to predict the next word in a sentence.
Technically, LLMs predict something called a "token".
A token is a small chunk of text.
Sometimes, a token is a full word, for example, "cat", "war", "men", etc.
Sometimes, instead of a whole word, a token is a part of a word. For example, the word "unbelievable" might be broken into three tokens: "un," "believe," and "able."
I'll explain tokens in detail in the next lesson. For now, I will use "words" instead of "tokens".
Let me show you what I mean.
Imagine the LLM is shown this sentence during training:
The chef sliced the onion with a sharp ___The training is set up so that the last word is hidden and the LLM is asked to guess it.
The fact is, the LLM doesn't know the answer at first.
So, it might guess "axe" or "blade" or "tool".

Why? Because the model is just starting out. It hasn't seen enough examples yet.
Having said that, during training, every time the model guesses wrong, it gets corrected.
Now here is where things get interesting.
When the LLM guesses "axe" but the correct answer is "knife," the model gets a signal that "your guess was wrong, and here is how wrong it was."
Behind the scenes, the model uses this signal to slightly adjust billions of internal numerical values.
These values shape how the model makes predictions.
They get tuned, just a tiny bit, to make the next guess slightly closer to the right answer.
And this is just one round of learning.
The LLM goes through this same "guess the word, get corrected" exercise billions of times, across billions of different sentences.
Each time, those internal values get adjusted just a little bit.
Sentence by sentence, the model's predictions get more accurate.
Gradient descent.
Buzzword, but the idea behind it is simple.
Nudge the dials in the direction that makes the next guess a little less wrong, and repeat billions of times.
And developers did not manually encode grammar rules one by one.
The behavior emerged through repeated optimization across billions of training examples.
But after all this training, what does the model actually know?
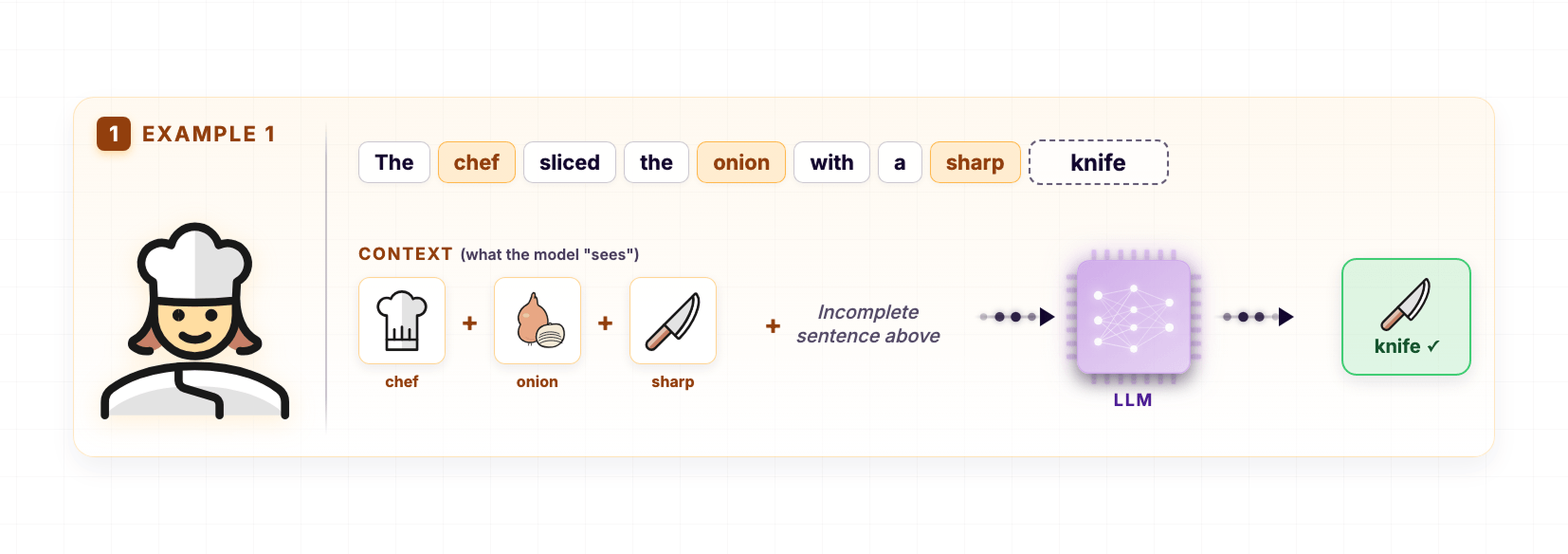
Let's get back to our chef example again 🍽️
The chef sliced the onion with a sharp Knife.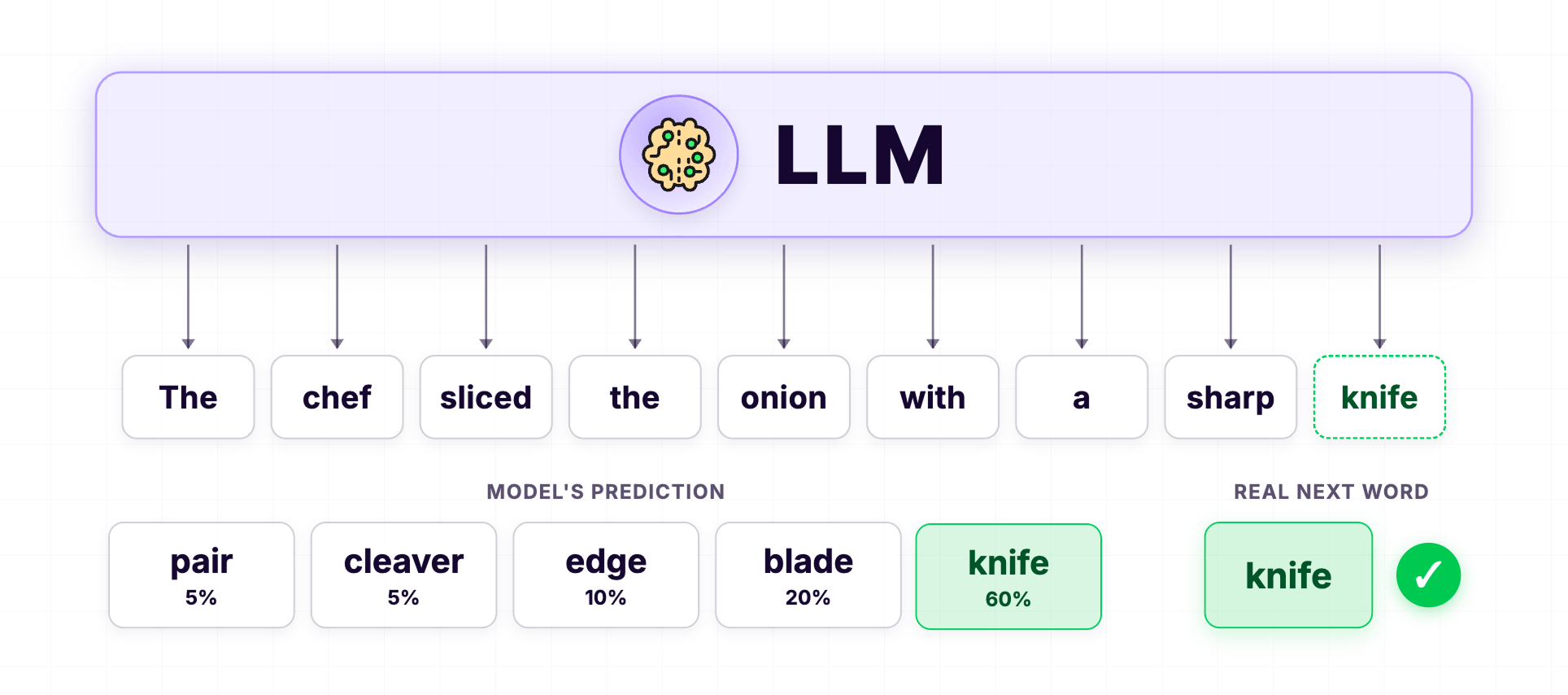
A trained model now predicts "knife" with high confidence.
Why?
Because during training, it saw thousands of variations connecting these concepts.
For example:
- The chef sliced the onion with a sharp knife
- The chef cut vegetables using a knife
- The knife was used to slice onions
- She picked up a knife and started chopping
Across all these variations, the model picked up on the relationship between chef, onion, slice, and knife.
But not the exact wording of any single sentence.
So when the model sees a new sentence with a similar context, "knife" gets a high probability.
Now look at these sentences:
The chef sliced the onion with a sharp ___
The surgeon made a careful cut with a sharp ___If you observe, both sentences end with the word "sharp."
Does this mean the LLM predicts "knife" for the surgeon sentence, too?
Nope.
The LLM predicts "scalpel."
The surgeon made a careful cut with a sharp scalpel.Why?
Because the full context is different: surgeon + cut + sharp.
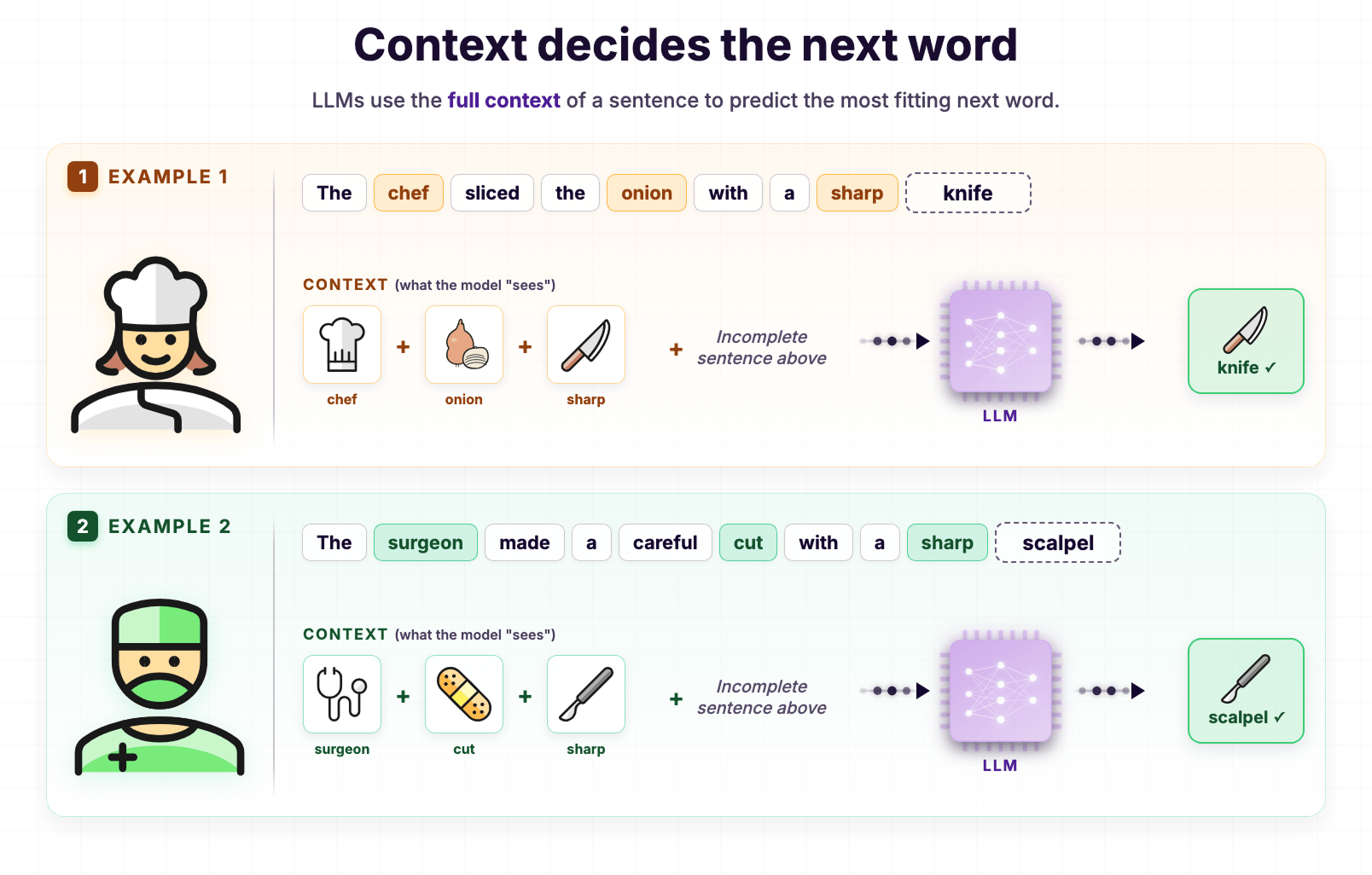
And during training, the LLM saw this kind of context paired with "scalpel" almost every time.
So it learned that "scalpel" is the better fit here.
The LLM is not picking the same answer every time just because the last few words match.
It is reading the entire sentence and picking the word that fits that specific context.
In other words, the LLM learns which parts of the sentence are important for predicting the next word.
Also, this is the basic idea behind how the LLM behind ChatGPT writes an entire article for you.
The LLM builds an entire article by predicting one word at a time, based on what it learned during training.
This also means that everything the LLM writes is a reflection of what it was trained on.
If it was trained on high-quality writing, it produces high-quality writing.
If it was trained on garbage, it produces garbage.
Also, a model doesn't have to be about text.
AI models can be trained on all kinds of data, such as images, videos, audio, and even DNA sequences.
The model is fed enormous amounts of one specific kind of data, and it learns the patterns of that data.
Only then can it generate brand new things in the same format.
In our case, an LLM is a model trained specifically on language. That is why it can read and write so well.
Anyway, this is what the word "Model" means in "Large Language Model."
Next...
What does the word "Language" mean?
A "Language" model simply means that the LLM has been specifically trained on human language.
And by "human language," I mean text such as:
- Books
- Internet articles
- Website content
- Day-to-day conversations from forums like Reddit
In other words, it is the kind of language we use every day to communicate with each other.
Companies share rough categories, but it is rare that they fully list the sources they used.
So when I say "trained on books and articles," I am just describing the general picture, not the verified list.
And as I said before, the regional language doesn't matter.
The LLM was trained on text from many languages.
Having said that, in 2026, the meaning of "Language" is becoming broader.
Modern LLMs are no longer limited to working with just text.
They have also evolved to work with images, voice, and video.
We call these modern LLMs Multimodal LLMs.
The word "modal" just means "type of media".
So multimodal = many types of media.
Think of a regular LLM as someone who can only read.
A Multimodal LLM is someone who can read, see, listen, and watch.
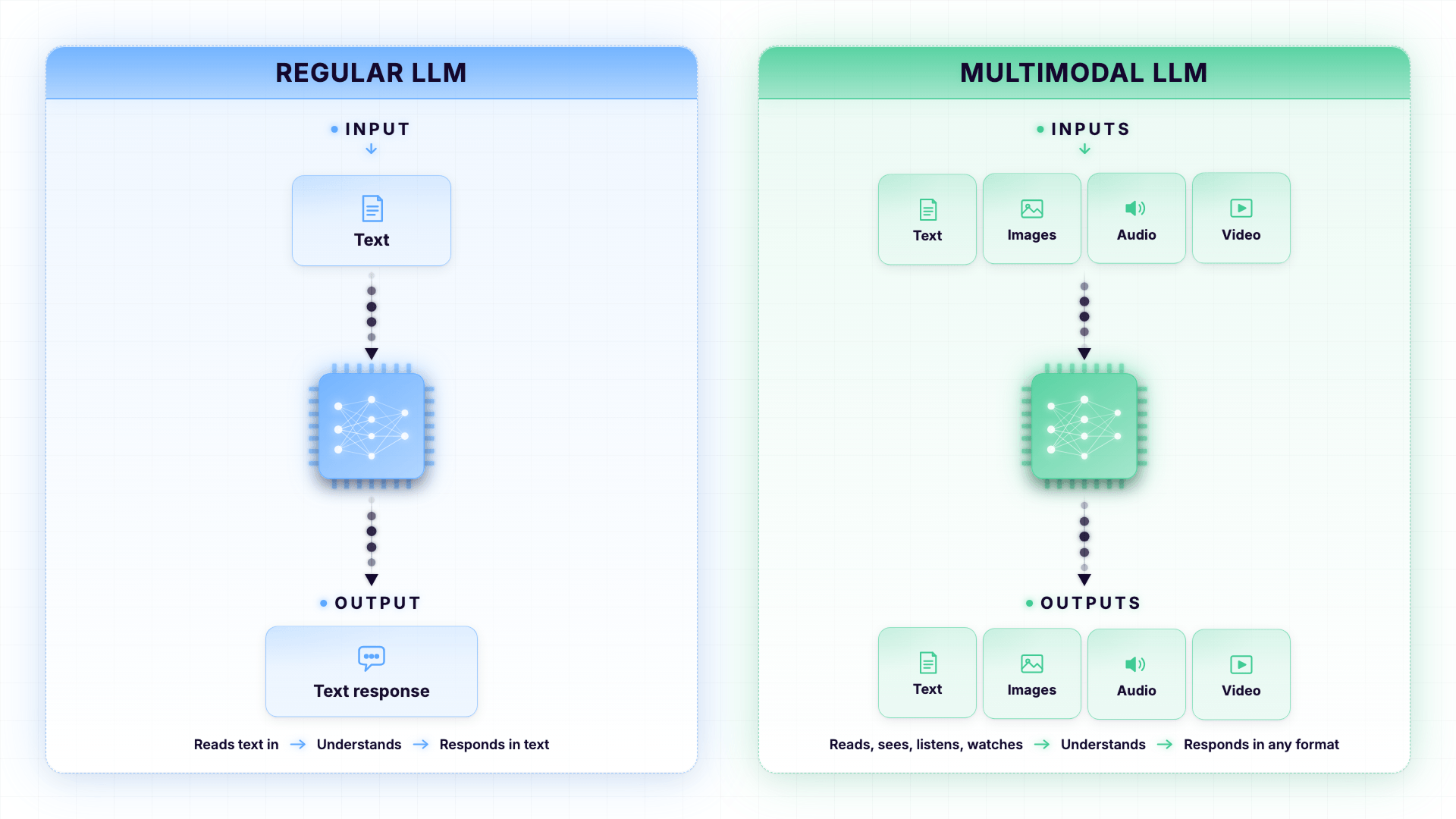
And honestly, you have probably already used a Multimodal LLM without realizing it.
Have you ever uploaded a photo to ChatGPT and asked, "What is in this picture?"
That is a Multimodal LLM at work.
It looked at the image and described it back to you in words.
Have you ever had a voice conversation with ChatGPT on your phone?
That is multimodal too.
The model listened to your voice, understood what you said, and replied to you out loud.
Pretty cool, right?
A few years ago, none of this was possible.
LLMs could only read and write text.
If you wanted to ask the AI about a photo, you had to describe the photo in words first. Now, you just upload it.
It's also important to know that the way multimodal models are built has changed.
The earlier multimodal systems were just text models with a separate "vision" or "voice" tool attached.
But now, recent GPT, Gemini, and Claude families are natively multimodal.
This means that they were trained on text, images, and audio together from the start.
This is part of why they feel more seamless and flawless when you switch between typing, uploading a photo, and talking to them.
This is a huge step forward because most of the things we deal with every day are not just text.
We deal with photos, voice messages, screenshots, videos, PDFs, and so on.
A Multimodal LLM can handle all these different types of inputs. Not just text.
And that is all you need to know about Multimodal LLMs for now.
Next...
What makes a language model "Large"?
The word "Large" tells you two things at once:
- The LLM was trained on a large amount of data
- The LLM itself has a large number of internal settings called parameters.
You need both for an LLM to be capable and usable.
Come on, let's quickly discuss them.
1) The LLM was trained on a large amount of data
If you train an LLM on a small number of books, let's just say, 10,000 books, it can do basic things.
For example:
- It can complete sentences
- It can answer simple questions
- It can write short paragraphs
But it struggles to perform complex tasks.
On the other hand, if you train the same model on 10 million books, it can do advanced things.
It starts to:
- Help you plan a 7-day trip from start to finish
- Help you debug code by figuring out where the error is
- Help you walk through a tough decision by weighing the pros and cons
- Help you understand complicated topics by explaining them simply
- Help you catch jokes, sarcasm, and metaphors
- Help you solve riddles
Researchers call this "emergent behavior."
Simply put, certain abilities only "emerge" once the model has been trained on enough data.
Some researchers believe the improvement is actually gradual, but it only looks sudden because of how we measure the model's performance.
Either way, larger models trained on more data generally become more capable.
"Okay! Wait. Are you saying these abilities were not directly programmed into the model?"
Yep!
No one wrote a rule that said: "if asked a riddle, here is how you should think about it".
No one programmed sarcasm detection.
No one taught the model to write poetry.
Heck, I don't understand sarcasm or poetry myself.
These abilities appeared because the model was trained on a huge amount of language and learned the patterns in it on its own.
This is why the size of the training data matters so much in the world of AI.
The bigger the training data, the more patterns the model can recognize.
The more patterns it can recognize, the more capable it becomes.
These are called scaling laws.
Another buzzword. I know. I know 🗡️
The basic finding is interesting too.
When AI companies increase:
- the amount of training data
- the number of parameters
- and the computing power used for training
The model’s performance usually improves in somewhat predictable ways.
This is one reason AI labs spend huge amounts of money training larger models.
They can often estimate how much better the next model might become before training even starts.
Crazy but true.
This is also why companies like OpenAI, Anthropic, Google, and Meta keep building models with larger and larger training datasets.
They are basically trying to unlock new emergent abilities.
But here is the interesting part.
The size and quality of the training data are only half the story.
The other half is the size of the model itself.
2) The LLM itself has a large number of internal settings called parameters.
Simply put, every AI model has something called parameters.
You can think of parameters as the model's internal settings.
Parameters are billions of numerical values that were fine-tuned during training.
Each parameter is like a tiny dial.
During training, the model adjusted these dials over and over again, getting just a little better at predicting the next word every time.
So when a model has more parameters, it has more dials.
More dials means the model has more "room" to capture subtle and complex patterns in language.
A model with very few parameters can only handle basic things like finishing sentences and answering simple questions.
A model with many billions of parameters can handle nuanced things like:
- Picking up tone
- Following complex instructions
- Working through multi-step problems.
In fact, the parameter count is so important that LLM names often include it right in the name.
For example:
- Llama 3.3 70B means it has 70 billion parameters
- Mistral 7B means it has 7 billion parameters
- Qwen 3 8B means it has 8 billion parameters
You will spot these "B" labels (which stand for "billion") all over Hugging Face, GitHub, and AI documentation.
So, the next time you see a model called "Llama 70B" or "Qwen 8B", you will know exactly what those numbers mean.
Roughly speaking, the parameter scale today looks like this:
- Small models typically have 1 to 8 billion parameters (like Mistral 7B, Llama 3 8B, Phi-3)
- Mid-sized models typically have 30 to 70 billion parameters (like Llama 3 70B, Qwen 32B)
- Some flagship models are believed to have hundreds of billions or more parameters.
That is a lot of dials.
So when we say "Large Language Model," we are actually talking about two things working together:
- An LLM trained on a large amount of data
- An LLM with lots of parameters
You need both of these to get the kind of capability we expect from modern LLMs.
If an LLM has lots of parameters but is trained on tiny data, it won't have much to learn from.
If an LLM is trained on lots of data but has very few parameters, it won't have enough brainpower to truly absorb everything it has read.
You get the idea, right?
Anyway, now that you understand what makes a Large Language Model "Large," let's talk about what these models can actually do.
More parameters does not always mean a better model.
In 2026, some 8-billion-parameter models outperform 70-billion-parameter models from a few years ago.
This is because the training data quality improved, the training methods improved, and the model architecture improved.
Parameter count is one important factor but please remember that it is not the only one.
So if you ever read that "this 70B model is bigger than that 8B model, so it must be better", that's not always true.
What can LLMs do?
LLMs can help you with a lot of variety of tasks.
And the list keeps growing as the LLMs improve day by day.
Let's talk about some of them quickly.
Vibe Coding
For example, you might have heard about Vibe coding.
Vibe coding is nothing but using plain English to build software applications and mobile apps.
Before LLMs became accessible to all of us, I used to write code for hours and hours using a programming language like JavaScript.
Now, I just provide instructions in English about what I want to code, and LLM writes the code for me.
For example, it took me 4 complete months to build a JavaScript code assessment tool using Svelte, a JavaScript framework.
But I asked an LLM (Claude Opus) to rebuild it from scratch using ReactJS instead of Svelte, and it took less than a day.
How powerful is that?
Not just coding, LLMs can help you with...
Writing tasks
- Drafting emails (cold outreach, follow-ups, replies)
- Writing blog articles, social media posts, and newsletters by maintaining your tone of voice
- Creating product descriptions for an online store
- Generating website content for landing pages, about us, and other usual business pages
Reading and summarizing tasks
- Translating text between languages
- Analyzing competitors' social media posts and telling you how to beat them.
- Summarizing a long PDF into digestible points that you can easily remember
- Explaining a research paper in simple language
- Extracting key points from a Zoom meeting
- Reviewing a contract and pointing out unusual clauses
Thinking and reasoning tasks
- Coming up with content marketing strategies
- Assessing and validating existing marketing plans
- Comparing two options (e.g., Mac vs Windows for video editing)
- Helping you plan a 7-day trip to Japan
- Walking you through a difficult decision
- To be honest, I have a major problem with taking a consultation from ChatGPT and hearing what I want to hear before making a bad decision 😜
Personal tasks
- Acting as a study buddy
- Helping you write a wedding speech
- Explaining a medical report in plain English (always verify with a doctor, though)
- Practicing for a job interview
And the list goes on and on...
Feeling powerful yet?
Anyway...
Here are some popular LLMs you should know about
GPT models by OpenAI.
GPT is the family of LLMs that powers ChatGPT.
The launch of ChatGPT in late 2022 is what pushed generative AI into mainstream public attention.
It is friendly, fast, and great for general use.
You can access it at chatgpt.com.
Gemini (by Google)
Gemini is Google's family of LLMs.
It is integrated into Google products like Gmail, Docs, and Search.
You can access it at gemini.google.com.
Claude (by Anthropic)
Claude is known for thoughtful, well-written responses.
It has two famous LLMs. Claude Opus and Claude Sonnet.
Opus is the advanced model.
It is especially good for programming. I personally believe it was trained for generating great code.
According to my experience, I get fewer bugs from Claude than from ChatGPT or Gemini. Your experience could be different.
Either way, you still need to verify and test the code, though.
Also, Claude LLMs are great for writing long-form articles and careful reasoning.
Personally, I like Claude's writing style for my articles and content work.
You can access it at claude.ai.
Other LLMs worth knowing
Kimi's suite of LLMs are open-source models that are gaining attention for generating reliable code, similar to Claude Opus.
According to my experience, it is still behind Opus in terms of code reliability and frontend UI code generation, but it is getting there.
Llama (by Meta) is another great open-source family of LLMs that developers can run on their own computers.
It is helpful for analyzing and talking with private data that you can't risk uploading to ChatGPT or Claude.
Next, there is Grok (by xAI). It is available inside the X (formerly Twitter) platform.
Finally, DeepSeek and Qwen, powerful LLMs from China, are growing in popularity.
As you can see, LLMs are everywhere. They are not rare anymore.
So, if you are just starting out, pick one (ChatGPT or Claude is a great first choice) and stick with it for a few weeks.
Once you get comfortable, you can try the others and see which one feels best for you.
And that's all for this lesson
You now have a solid foundation. You know what an LLM is, why "Large" matters, and what kinds of things LLMs can do.
But I've been simplifying a few things to make this easy to follow.
Let's go one level deeper now and look at three things every LLM user should understand:
- What tokens actually are (and why I kept saying "word" loosely earlier)
- How Transformers, the engine inside modern LLMs work
- Why does ChatGPT feel helpful and conversational even though all the LLM does is "predict the next token"?
We will cover these in the next lesson.



